

What is GitOps?
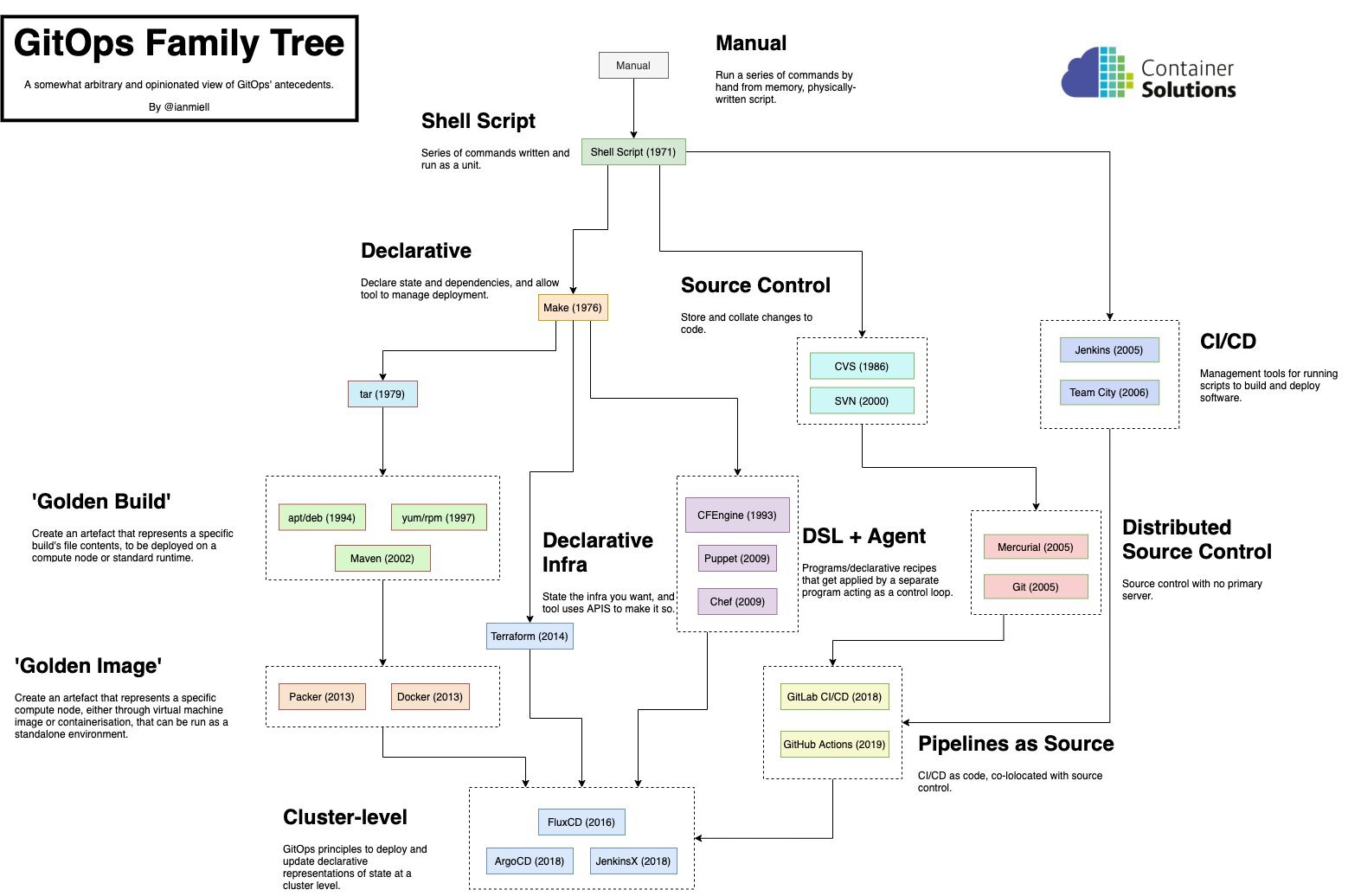
Diagram by Ian Miell
This is a guest post by Justin Domingus, co-author with John of the Cloud Native DevOps with Kubernetes book.
Once you've wrapped your head around the basic concepts of Kubernetes, the next question that often comes to mind is “So how can I deploy my services onto this thing?” That means we need to talk about Continuous Integration/Continuous Deployment/Delivery (CI/CD) pipelines.
Kubernetes itself is a great platform for running reliable services, but it also comes with a growing ecosystem of tools for managing deployments that can help improve the workflows of both software developers and cluster operators.
Software engineers have certainly been running and deploying software long before Kubernetes, Docker, and cloud platforms ever existed. So what's different about the cloud native world?
“GitOps” is the latest newcomer to the conversation about how to manage changes to applications over time. Ian Miell is working on an upcoming book specifically about GitOps and made this helpful diagram called “The GitOps Family Tree”.
GitOps is a new addition to the family that includes shell scripts, Makefiles, Dockerfiles, Jenkinsfiles, building reusable images with Packer, infrastructure-as-code tools like Terraform, and configuration management tools such as Ansible, Puppet, and Chef. And GitOps brings some new tools to this ecosystem for managing containerized applications in Kubernetes clusters.
Although the term 'GitOps' itself is relatively new, the idea had been around for a long time before Weaveworks (the folks behind Flux and eksctl) coined a word for it.
The idea is to bring together the processes of deploying code and managing that code with version control (git being one of the more popular source control tools in use these days).
Instead of keeping your code in a Git repository and then running some command or process to manually deploy changes from it, when you do GitOps you are automatically deploying whatever is at the head of that repo. So 'deployment', for you as a developer, means simply merging a pull request, and the automation does the rest.
This means maintaining a single Git repository that contains all of your Kubernetes manifests, both for your own applications, along with any supporting services you need to install, such as prometheus for metrics, fluentd for logs, or cert-manager for managing TLS certificates. Because everything is in one place, it's easy to manage, and there's a single audit trail that shows who changed what, when, and why in the git commit history.
Adding a new application to your clusters can be as simple as opening a PR to this central “configuration repo” containing the Kubernetes manifests or Helm charts for your new service. Once that PR is approved by your team and merged, a GitOps tool (like Flux or Argo) can automatically apply that change from within the cluster.
This is the same kind of workflow that many people use with traditional servers and configuration management tools like Puppet, Chef, Salt, or Ansible. The configuration of every server is declaratively managed by code in a Git repo, and whatever is merged to that repo is automatically rolled out across the whole infrastructure. This is GitOps, and tools like Flux simply extend this pattern to include Kubernetes.
One popular workflow that GitOps tools can provide is to automatically deploy upgrades whenever a new container image is pushed to your container image registry. Imagine a testing cluster where your GitOps tool could automatically deploy new container images of your app as soon as they are built and published to the registry. The GitOps tool would automatically make a commit back to the central configuration repo when the deploy is finished setting the newly applied container tag.
A common problem with Kubernetes is how to recreate the 'state of the cluster'. It's not that you actually often need to rebuild a cluster from scratch, but the point is that in a declarative infrastructure there should be an automatable way to do that. Otherwise, recovering from disasters is a complex and error-prone manual process which may rely on information you no longer have available.
The centralized config repo and the GitOps tooling offers a way to deal with that. Simply install your GitOps tool, point it at your repo, and it will automatically reinstall everything using the last deployed versions, bringing the cluster back to a state where it's ready for production. It's rare to be able to make this entirely automated, because there is usually also some data in the system, such as your user database, or uploaded assets, for example. But using the GitOps discipline certainly helps with everything that can be managed declaratively, leaving you more time to deal with the stuff that needs human intervention.
To learn more and get started with GitOps we recommend checking out Flux and Argo. These are separate (but similar) GitOps tools for now with slight differences in functionality, but in November of 2019, the two teams announced that they are going to collaborate on a single shared tool that will be called the GitOps Engine.
For now, try installing either Flux or Argo (or both if you are feeling up for it!) and get a feel for how they work. You can find the Getting Started docs for Flux here and for Argo here.




